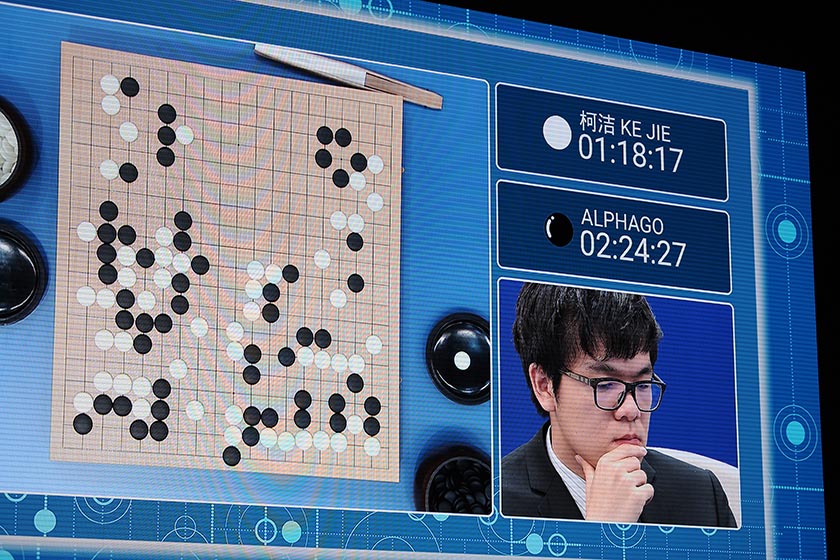
【财新网】(专栏作家 张小彦)最近报道的阿尔法元(AlphaGo Zero)仅用三天自学成才达到目前人类围棋最高水平,震惊世界。更为重要的是它在零数据输入的状态下完成了这一任务,而不像上一代阿尔法狗 (AlphaGo) 通过学习海量人类的棋谱。
围棋游戏有棋盘,有规则,胜负明确,目标单一,其本质是透明规则的数学计算。实际生活,特别是社会管理决策就没那么简单了。但是,被阿尔法元证实的人工智能自学能力却对社会层面宏观预测和管控有重要的启示。

【财新网】(专栏作家 张小彦)最近报道的阿尔法元(AlphaGo Zero)仅用三天自学成才达到目前人类围棋最高水平,震惊世界。更为重要的是它在零数据输入的状态下完成了这一任务,而不像上一代阿尔法狗 (AlphaGo) 通过学习海量人类的棋谱。
围棋游戏有棋盘,有规则,胜负明确,目标单一,其本质是透明规则的数学计算。实际生活,特别是社会管理决策就没那么简单了。但是,被阿尔法元证实的人工智能自学能力却对社会层面宏观预测和管控有重要的启示。
责任编辑:张帆
版面编辑:张翔宇
观点频道所发布文章及图片之版权属作者本人及/或相关权利人所有,未经作者及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括上述文章及图片。文章均为作者个人观点,不代表财新网的立场和观点。
AlphaGo在围棋界“孤独求败”,Deepmind再出新一代机器人
2017年10月19日